About dotcloud
The first time I heard about DotCloud was about two months ago, in the beginning of 2011. I was very tempted to try it as soon as possible but it seems there were a very lengthy queue of people like me so I had to wait for quite some time. But finally I've got my account activated few days ago.
I was so happy about that so initially I didn't even know what application to try to develop on it, as I wanted to cover as much services as possible that DotCloud offers. After all, I decided to go with a frontend Django application and several workers communicating with each other using messaging as it seems to be a good basis for a lot of things I have to do these days.
Originally I wanted to use RabbitMQ server, but unfortunately it's not working for some reason, which made me take a look at celery with redis backend. I have never used neither celery nor redis so it was even more interesting to learn these things as well.
So I came up to a scheme like these.
Sample Application
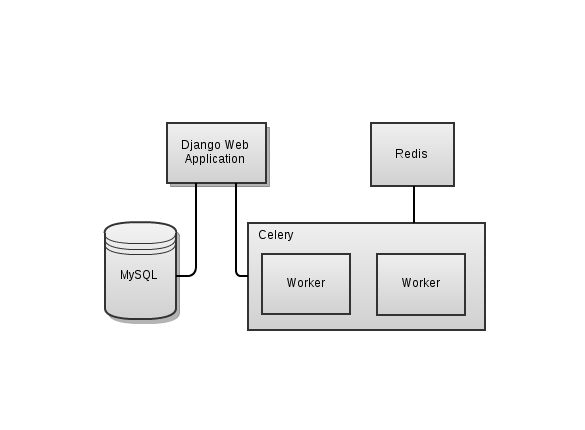
* Django Web Application provides a user interface for issuing tasks and obtaining their results
* MySQL is used to keep history of issued tasks
* Celery handles all task-related operations. It passes tasks to Workers for execution using Redis as transport layer and results are stored also in Redis
As for the task, I choose a really simple one: just sending 60 ICMP ECHO_REQUEST packets to determine if a host specified by user up or down. Use case is simple: user opens up a page, specifies a host to ping and then waits for result and it appears to him after some time.
Workers Implementation
I have started with workers implementation. I followed Tutorial on DotCloud web site to create my first Celery worker and it worked alright, but I had step from it several times for the following reasons:
RabbitMQ service problems
When I created a rabbitmq service it for some reason had empty ports list, like that:
$ dotcloud info bublick.rabbitmq
cluster: wolverine
config:
password: password
rabbitmq_management: true
user: root
created_at: 1303573502.963711
name: foo.rabbitmq
namespace: foo
ports: []
state: running
type: rabbitmq
$
I thought it was some glitch, especially considering that this happened not long ago after EC2 outage (and DotCloud runs on top of EC2). So I tried to drop this service and deploy a new one. Alas, everything was same. I joined an IRC channel -- #dotcloud on freenode -- to ask what's wrong with that and it appeared that it's a known problem and is going to be fixed soon.
It's not a big deal though, because Celery supports a lot of brokers in addition to RabbitMQ, so I decided to go with Redis and use it to store results as well. So I just changed celeryconfig.py to point to Redis instead of RabbmitMQ:
Then I implemented actual task which pings a given host:
As you see, it's pretty trivial.
However, I've spotted a problem when I tried to push the code, basically it said that 'celeryd' could not be started.
So I've logged in to VM running celery using the command 'dotcloud ssh foo.celery' (where foo.celery is a name of deployment) and tried executing 'celeryd' by hand, and it failed with 'Permission denied' error. I asked on IRC channel again and it was a known problem also, and it was quickly fixed for my deployment.
After that my worker was fully functional, you can check sources and its celery configuration here: https://github.com/novel/dotcloud-sample-app/tree/master/worker.
Then I moved to web application.
Web Application
As it was mentioned, I wanted to use Django framework for web application. Luckily, there's a tutorial on django deployment on dotcloud as well. I followed this tutorial step by step and sample django application deployed smoothly.
Then I needed to add celery integration. As I deployed code separately I didn't want to import actual task code but call by name. Also, I wanted task status to be fetched only when user actually requests it, so I had to find tasks by id.
The first steps is to configure django application to use celery. It's done by adding django-celery and redis dependencies to requirements.txt and defining celery stuff in settings.py:
.
And finally set of simple views to schedule tasks and report their status:
You can also see a view which provides a list of active workers. Now, if you deploy your web application and the worker thing should work fine. Additionally, you can add extra workers seamlessly. For example, if you named your worker 'foo.celery', you can add more workers exactly the same way, just use e.g. foo.celery2 etc for dotcloud deploy and dotcloud push commands.
Things to keep in mind
* PYTHONPATH contains only top level project directory by default, so one either should add django application to PYTHONPATH or use full path for modules, e.g. pay attention I have my 'ping' application listed in settings.py as 'frontend.ping' for example, otherwise it won't work
* You don't have to add database drivers like mysqldb-python to requirements.txt since they're available by default
DotCloud first impressions
* Documentation is good, fairly complete, I haven't seen an outdated or misleading information
* DotCloud guys are very helpful, all the questions get addressed very quickly on the IRC channel
* Great jobs done with the services. For example, I have never ever used redis and I have no idea how to set it up and configure. All I had to do is to run dotcloud deploy -t redis foo.redis and it's there, very good. The same goes for wsgi deployment -- it's a shame, but I've never did such type of deployment myself, I just use 'manage.py runserver' for local testing... it's good to have a deployment engineer on the team! :) So, it also went seamlessly, I don't even have to know where logs are located, I just do 'dotcloud logs foo.www'.
* Some services are unstable or not working, like RabbitMQ (which is unusable) and Celery (which needs some manual actions from support team to work fine). That doesn't seem to be a serious problem to me though, considering that DotCloud is at beta stage currently, and more over they must have been very busy last few days recovering from EC2 outage.
Things I'm curious about
* Currently, there's no way to install system-level package (like, say, ImageMagick. It way mentioned on IRC that popular packages like that will be eventually included into base images based on users requests. I'm curious how it will be done without letting images spreading out.
* I need to research how scaling is implemented and choosing scaling strategy looks like
* I wonder how upgrade strategy looks like. FAQ says that upgrades are "prudent and thoroughly tested" (c) but everyone knows that things can always break in some totally unexpected ways and what are the procedures for rolling back, sticking to specific version of the components and so on.
* I wasn't able to find if there are any monitoring facilities provided. Also it's not clear what's going to happen if some critical component or VM goes down.
Conclusion
It was fun to experiment with DotCloud and I'm going to spend some more time on it. It differs from services that I worked with before. I've got an impression that its abstraction level is somewhere higher that IaaS but lower that a typical PaaS. On the one hand, you don't have to worry about things you usually have to worry on IaaS, like installation and configuration of services like MySQL and so on. On the other hand, you still have to do a fair amount of deployment-related things, like creating databases, configuring users, manually running syncdb commands and other things you typically don't do on PaaS. Also, you can view almost everything you might need as you have ssh access to every VM, but you cannot change almost anything since it's not root access.
So I'm definitely interested to see how DotCloud evolves and hope to spend some more time using and learning it.
References
Sample Application
Sample application I've used as a sample could be found on github: https://github.com/novel/dotcloud-sample-appClone it:
git clone git://github.com/novel/dotcloud-sample-app.gitAll you need to run it now is to put credentials for you mysql and celery services and deploy it on DotCloud. Have fun!
Further Reading
* DotCloud FAQ* DotCloud Django Tutorial
* DotCloud Celery Tutorial
* Celery Documentation
* Django-celery Documentation
* Sample App